
학위 논문 진행 상황: 3회차(2024.03.06)
1. 지난 주간의 요약
[완료된 작업]
- Llama 연구
- 예비 연구 방향 설정
[진행 중인 작업]
- 파이썬 초보자의 실수 데이터 수집 => (변경) 사내 온라인 저지에서 파이썬 초보자 코드 데이터 수집
3. 이번 주간의 진행 상황
[완료된 작업]
Llama 연구: [단계1] 문헌 조사 및 관련 내용 학습: Code Llama에 관한 10회차 문헌 조사에서 해당 논문을 리뷰하고, 유튜브와 블로그를 통해 모델 사용법을 익혔습니다. 국내 자료의 부족으로 대부분 외국 자료를 참고해야 했으며, 이로 인해 탐색과 이해에 다소 노력이 필요했습니다.
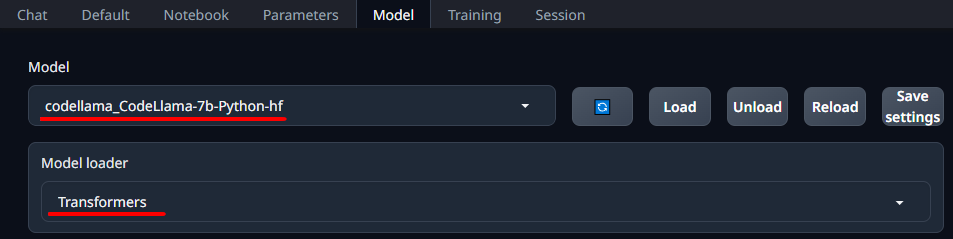
[단계 2] 환경 설정: Meta가 배포한 작지만 강력한 CodeLlama-7b-Python 모델을 Google Colab에서 실행하려 했으나, 가상 디스크의 용량 문제로 로컬 환경에서 실행할 방법을 탐색했습니다. 이 과정에서 GitHub의 textgeneration web ui(/oobabooga/text-generation-webui)를 통해 LLM 모델을 쉽게 사용할 수 있는 웹 UI 코드를 발견했습니다. Huggingface(AI 커뮤니티)에서 CodeLlama-7b-Python-hf 모델을 다운로드 받아 Transformers 기반으로 업로드했고(그림 1 참조), 기본 설정으로 파라미터를 조정한 후, Instruct 모드로 프롬프트를 설정했습니다
그림 1. textgeration web ui의 환경 설정 화면
[단계 3] 실험 1-잘못된 코드 생성 지시: 논문 저자가 사용한 프롬프트를 기반으로 커스텀 프롬프트를 작성하여 실험했고, 모델이 잘못된 코드를 생성하는 것을 확인했습니다.

[단계 4] 실험 2-올바른 코드 생성 지시: 단계 3에서 사용한 지시문을 수정하여 동일한 요청으로 올바른 코드 생성을 유도했고, 모델이 정확한 코드를 생성하는 것을 확인했습니다.

[단계 5] 실험 3-프롬프트에 파이썬 초보자 설명을 추가하고 상위 문제에 대한 잘못된 코드 생성 지시: 이전 단계에서 테스트한 것보다 더 어려운 문제를 선택하고, LLM이 초보자를 이해할 수 있도록 해당 대상의 설명을 추가하여 잘못된 코드 생성을 유도했습니다. 결과적으로 잘못된 코드가 생성되었으나, 기대했던 리스트 관련 오류 대신 단계 3에서 확인된 매우 기초적인 실수가 반복되어 나타났습니다. 프롬프트를 다양하게 조정하고 실험했음에도 불구하고, 비슷한 수준의 실수가 지속적으로 발생했습니다.

[단계 6] 실험 종료-주어진 문제에 초보자 입장에서 저지를 만한 실수를 Comment 하도록 추가 지시: Llama가 제공한 코멘트가 문제와 관련 없었고, 더 이상 잘못된 코드를 생성하지 않았기 때문에 실험을 종료했습니다.

[결론] Code Llama는 올바른 코드 생성에서 강력하지만, 의도적으로 잘못된 코드를 생성하는 작업에서는 퍼포먼스가 상당히 떨어짐: Code Llama는 코드 생성을 목적으로 설계된 모델이므로, 파이썬 초보자가 범할 수 있는 오류를 포함한 잘못된 코드 생성을 유도하는 프롬프트에 대해 예상한 반응을 보이지 않았습니다. 반면, 비슷한 프롬프트를 GPT에 적용했을 때는 GPT가 의도에 맞게 반응했습니다. 이를 통해 제 연구에서 Code Llama를 데이터 생성 도구로 사용하기에는 적합하지 않다는 결론을 내렸습니다.
예비 연구 방향 설정: Code Llama를 활용한 코드 데이터 생성이 적합하지 않다는 결론이 나와 데이터 수집 범위를 사내 온라인 저지에서 수집한 파이썬 코드 데이터로 한정하는 전략을 세울 수 있었습니다. 이러한 어려움은 되려 웹 시스템 구현 시 온라인 저지 기반 모델을 고려하게 하는 근거가 되었습니다.
[진행 중인 작업]
사내 온라인 저지에서 파이썬 초보자 코드 데이터 수집: 기존의 DataFrame을 문제 설명에 초점을 맞춰 수정했습니다(그림 2 참조).

수정 후, Quanjun Zhang이 AtCoder 대회에서 사용한 2023년 문제와 제출 데이터 수집 방식을 참고하여 데이터를 수집하고 있습니다.
- 원시 데이터 수집: 2021년부터 시작된 사내 온라인 저지에 Python으로 제출된 코드 중 정답률이 50% 이하인 문제와 해당 제출 코드를 수집
- 정적 기반 필터링: 반복 제출된 코드를 제거하고, 코드 내 주석을 삭제해 GPT 판단에 영향을 주지 않도록 작업. 이러한 데이터 중에서 GPT 파인 튜닝에 사용할만한 유의미한 데이터를 필터링
정적 기반 필터링은 주기적으로 수행되고 있으나, DB에 사용자 ID가 기록되어 있어, 지정된 작업자인 저만이 필터링 작업을 할 수 있습니다. 또한, 반복 제출 코드나 학습 데이터로 적합한지를 판단하기 위해서는 직접 검토가 필요합니다. 이로 인해 데이터 수집은 3월 첫 주까지로 한정하고, 목표는 최소 100개의 유의미한 데이터를 확보하는 것을 목표로 했습니다. 현재는 60개까지 확보했습니다.
4. 다음 주간의 계획
- 파이썬 초보자의 실수 데이터 수집: 다음 단계 연구 수행을 위해, 3월 첫 주까지만 데이터를 수집하려 합니다.
- 코드 피드백 모듈을 위한 프롬프트 설계: 수집한 데이터를 사용하여 효과적인 코드 피드백을 제공하기 위해 필요한 프롬프트를 설계할 예정입니다.
- 프롬프트 엔지니어링을 통한 피드백 생성 및 수집: GPT-3.5를 사용해 피드백을 생성하고, 교육 전문가의 평가를 위해 결과를 수집할 예정입니다.
댓글남기기